Celesta Steering Committee Members
These are members whose votes are counted during the Celesta Improvement Process (in alphabetical order):
CIP-1
Metadata
CIP |
1 |
|---|---|
Title |
Celesta Improvement Proposal Format |
Author |
|
Created |
2019-05-22 |
Status |
implemented |
Discussion |
https://groups.google.com/forum/#!topic/celesta-dev/gDc2MvHu2SM |
JIRA |
N/A |
Motivation
Since Celesta Project is acquiring larger user base, it becomes impossible for any single person to control all the aspects of its possible usage. Any compatibility-breaking changes in Celesta, although desirable for some users, can be harmful for others.
Thus a wide discussion of every change is needed in such a way that different Celesta users' needs can be considered and met.
Furthermore, this discussion should facilitate the spread of information about new features of Celesta. Not only the immediate authors of the change proposal should benefit from the implementation of their ideas, but as large number of other users as possible.
In order not to miss any interested parties, we should set the formal rules of such discussion: where and how it should be carried out.
Last but not the least: we need a resilient process for Celesta development, not dependent on availability of any single person.
Proposed Changes
-
Each change that modifies public API or breaks backwards compatibility should pass the CIP process.
-
The change should be formally written in the form of 'CIP' document. This document must be written in .adoc format, and committed to https://github.com/courseorchestra/cip project. If an author of the CIP does not have rights to push to CIP project directly, they can submit their CIP in pull request and request the rights from project owners: in order to simplify the process, rights to CIP project are given away freely.
-
CIP document should be written using the provided template, and must contain the following sections:
-
Metadata — CIP number, title, author, status, links to discussion, related JIRA ticket and so on.
-
Motivation — describes the problem we are trying to solve
-
Proposed Changes — describes the solution for the problem, i. e. the formal specification, according to which the changes must be implemented.
-
Compatibility, Deprecation, and Migration Plan — in case backwards compatibility is broken, all the necessary upgrade steps should be described.
-
Rejected Alternatives — if during the discussion the proposed solution is rejected in favour of another one, the CIP should be rewritten and the rejected solution should be moved in this section.
-
-
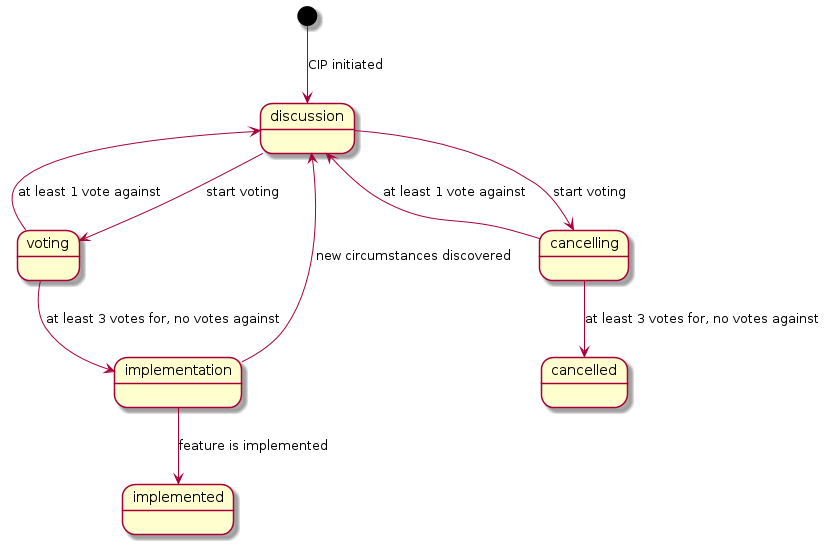
After submitting the CIP, the author of the CIP should start the discussion, by writing approximately the following to https://groups.google.com/forum/#!forum/celesta-dev/ group: 'Hello, I would like to start a discussion for <insert the link to CIP here>. The status of the CIP should be set to discussion. Any person can join the discussion.
-
There are two ways to carry out the discussion of CIP:
-
via email on
celesta-devgroup in replies to the initial letter -
collective Skype/Hangouts call, with concise follow-up sent to
celesta-devgroup. NB: it is obligatory to send a follow-up for each call tocelesta-group, so that any decision made is documented.
-
-
During the discussion phase either a consensus on how to implement the proposed feature is reached, or the initial proposal is rejected. In the second scenario, the CIP’s author should update the CIP and move the rejected ideas into the appropriate section, and then re-initiate the discussion.
-
If the consensus is reached, CIP’s author changes status to 'voting'. Only votes from members of Steering Committee is counted. In order to pass the CIP to development, at least three votes from members of Steering Committee is required. If any of the members of Steering Committee is voting against the proposal, it is turned back to the discussion.
-
Sometimes during the discussion it is agreed that the proposed change should not be implemented at all. In this case CIP receives the 'cancelling' status and voting for cancellation starts, with the same rules as voting for implementation.
-
After three members of Steering Committee vote for the CIP’s implementation, the CIP is finalized and implementation phase starts. Any changes
-
If new circumstances / difficulties are discovered during the implementation process, the CIP can be returned to 'discussion' phase.
-
When the feature is implemented, the CIP receives 'implemented' status. Most of its 'proposed changes' section should be copied to Celesta User Guide. No further change to the CIP is allowed.
Compatibility, Deprecation, and Migration Plan
N/A
Rejected Alternatives
None
CIP-2
Metadata
CIP |
2 |
|---|---|
Title |
Dynamic Data Change for Cursor |
Author |
|
Created |
2019-06-22 |
Status |
Implemented |
Discussion |
https://groups.google.com/forum/#!topic/celesta-dev/I7jtbrEKv60 |
JIRA |
Motivation
In course of Cymbals project implementation which is using Celesta as one if its integral parts, it was noted that Celesta was lacking API for setting dynamically formed testing data to its cursors, for such data were obtained during run-time rather than in a static way. To overcome this problem a workaround solution based on a reflection mechanism of Java had to be provided that neither can cover all desired cases, nor is durable. It is believed that handling of similar use case could have a demand from other projects.
Proposed Changes
To extend API by adding
BasicCursor.setFieldValue(String fieldName, Object value)which would perform a type check and set the value.
Cursor Table.getCursor(CallContext ctx)
ViewCursor View.getCursor(CallContext ctx)
Sequence SequenceElement.getSequence(Context ctx)
ParameterizedViewCursor ParameterizedView.getCursor(Context ctx)
MaterializedViewCursor MaterializedView.getCursor(Context ctx)methods for getting appropriate cursors of grain elements.
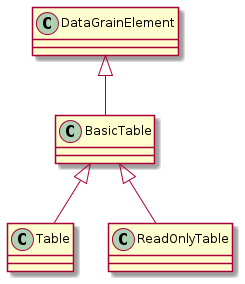
It should be noted that currently class Table can both represent tables with and without write access who are distinguished by Table.isReadOnly() property that returns true for read-only tables and false otherwise. Read-only tables in turn are using ReadOnlyTableCursor as a base class for their cursors. It is proposed to extend the table class hierarchy by including a separate ReadOnlyTable class, and have both Table and ReadOnlyTable be inherited from BasicTable:
Compatibility, Deprecation, and Migration Plan
Table.isReadOnly() property should be marked as deprecated and should always return false.
Methods for working with meta-information in Celesta already exist:
Grain Score.getGrain(String name)
T Grain.getElement(String name, Class<T> classOfElement)they should be used in implementation.
Rejected Alternatives
None
CIP-3
Metadata
CIP |
3 |
|---|---|
Title |
Interface specification for cursor classes |
Author |
|
Created |
2019-06-27 |
Status |
discussion |
Discussion |
N/A |
JIRA |
N/A |
Motivation
Sometimes it is useful to have some of the cursor classes implement the common interface, e. g. in situations where different tables have similar subset of columns. E.g. when we want to be able to use a single procedure to process data from different tables, and we want the type of the argument of this procedure to be a common interface.
Proposed Changes
1. Use Celestadoc to mark the cursor interfaces
Add the possibility to mark the needed interfaces in CelestaDoc, like following:
/**{interfaces: ["ru.curs.project.package.Intf"]}*/
CREATE TABLE T1 (
foo int,
bar varchar(10),
baz int);In this case, the cursor source code generator should generate the cursor class the following way:
import ru.curs.project.package.Intf;
class T1Cursor extends BasicCursor implements Intf {
...
}The ru.curs.project.package.Intf should be defined somewhere in a way to be compatible with generated T1Cursor, e. g.
interface Intf {
int getFoo();
String getBar();
}2. Introduce interfaces for BasicCursor and Cursor
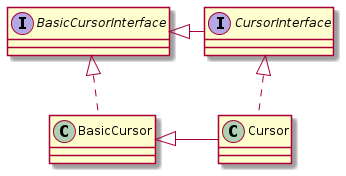
Extract all public methods from BasicCursor into BasicCursorInterface and Cursor into CursorInterface, make these interfaces publicly available in the same package with Cursor and BasicCursor:
Usage examples
If two or more cursors implement the same interface, users then may use intersection types to write the 'universal procedures', like
<T extends BasicCursor & Intf> void myProc(T cursor){
cursor.findFirst(); //inherited from BasicCursor
cursor.getFoo(); //inherited from Intf
}If a shared interface is inherited from BasicCursorInterface or CursorInterface, then there is no need in intersection types. We plan to use these interfaces in Lyra project.
Compatibility, Deprecation, and Migration Plan
Since API is extended backwards compatibility is fully preserved.
Rejected Alternatives
Introduction of special CREATE INTERFACE construction into CelestaSQL
CREATE INTERFACE Intf (foo int, bar varchar(10));
CREATE TABLE T1 (foo int, bar varchar(10), baz int) WITH INTERFACE Intf;
CREATE TABLE T2 (foo int, bar varchar(10), bee int) WITH INTERFACE Intf;Pros: Less source code (interface code is going to be auto-generated). We can control the interface-to table compatibility during the SQL parsing stage and fail fast in case of incompatibility.
Cons: This is not standard SQL, not supported by any editors/tools. We tend to make CelestaSQL as 'standard' as possible. As for table-to-interface compatibility check, it will be done by Java compiler anyway.
CIP-4
Metadata
CIP |
4 |
|---|---|
Title |
Type checking for setRange/setFilter |
Author |
|
Created |
2019-06-30 |
Status |
implemented |
Discussion |
https://groups.google.com/forum/#!topic/celesta-dev/2ScUhSqng8w |
JIRA |
Motivation
When working with generated Celesta cursors developer have to indicate cursor fields as string literals, eg. FooCursor.setRange("bar_open", true), which is fragile when the corresponding field of the grain is renamed. So it’d be nice having all grain fields be defined as constants in the generated cursors.
Proposed Changes
-
Make
Columnclass parameterized by the type of its value (Column<T>), and rewrite each of its descendants the following way:IntegerColumn extends Column<Integer>,StringColumn extends Column<String>etc. -
Define all the columns of the table in the respective
final staticconstants of the Cursor. Fill them in static initializer. -
Make
setRangeandsetFiltermethods parameterized and use the type capture, e. g.:
<T> void setRange(Column<? super T> column, T from, T to)
This will give us full type checking for setRange and setFilter.
Compatibility, Deprecation, and Migration Plan
None. Leave old versions of setRange and setFilter in the BasicCursor along with new ones.
Rejected Alternatives
Having all the table fields' names defined as constants in the generated cursors — better than nothing, but still does not provide us with strict static checking.
CIP-5
Metadata
CIP |
5 |
|---|---|
Title |
Multiple Celesta instances support and score namespaces filtering |
Author |
|
Created |
2019-09-09 |
Status |
discussion |
Discussion |
https://groups.google.com/forum/#!topic/celesta-dev/40OIdAd44Hw |
JIRA |
N/A |
Motivation
Currently Spring Boot based projects can only use a single instance of Celesta which significantly restricts the applicability of Celesta in data handling and migration for other RDB data sources. As a workaround additional Celesta instances have to be explicitly provided for example as spring beans and be managed manually.
Proposed Changes
-
Enhance spring-boot-starter-celesta so that configuration
celesta:
... # configuration for default data source
datasources:
- name: 1st_data_source
... # configuration for 1st_data_source
- name: 2nd_data_source
... # configuration for 2nd_data_source
...could be accepted.
-
Make annotation
@CelestaTransactionparameterizable with a data source name, e.g.@CelestaTransaction("2nd_data_source"). If such parameter is missing assume the default Celesta instance is used. -
Introduce additional Celesta properties:
score.includeandscore.excludethat would take a list of namespaces (dot-separated path to a grain sql-file(s)) to include/exclude a single or a group of grain sql-files.
score.include=ds1.** # include all grain sql-files from 'ds1' namespace recursively
score.exclude=ds1.seq,ds1.test.* # exclude 'ds1/seq.sql' and 'ds1/test/*.sql' but leave e.g. 'ds1/test/important/**'score.exclude has precedence over score.include.
|
When having several data sources it is important not to mix up different grains for different data sources hence these properties are needed. |
Compatibility, Deprecation, and Migration Plan
None.
Rejected Alternatives
None.
CIP-6
Metadata
CIP |
6 |
|---|---|
Title |
Call context factory support for simplifying code in Spring Boot based applications |
Author |
|
Created |
2019-12-03 |
Status |
discussion |
Discussion |
https://groups.google.com/forum/#!topic/celesta-dev/tX0mnYZDvW0 |
JIRA |
N/A |
Motivation
When writing Spring Boot based application with a Celesta integration based on spring-boot-starter-celesta project, a very common coding pattern occurs:
import ru.curs.celesta.SystemCallContext;
...
@RestController
@RequestMapping(API_PATH)
public class DemoController {
static final String API_PATH = "/demo";
static final String CYMBALS_PATH = "/cymbals";
static final String GET_SPEC_PATH = "/getspec";
...
@GetMapping(path = CYMBALS_PATH + GET_SPEC_PATH)
public String getSpecification() {
return cymbalsService.getSpecification(new SystemCallContext());
}
...
}import ru.curs.celesta.CallContext;
...
/**
* Service for integration with Cymbals library.
*/
public interface CymbalsService {
...
String getSpecification(CallContext callContext);
...
}import ru.curs.celesta.CallContext;
...
@Service
public class CymbalsServiceImpl implements CymbalsService {
...
@Override
@CelestaTransaction
public String getSpecification(CallContext callContext) {
CalcSpecCursor cursor = new CalcSpecCursor(callContext);
...
}
...
}which clutters service API code with CallContext parameters and makes the architecture cohesion inconsistent, that is the decision what persistency implementation to use should be taken in business layer (services) and not in presentation one (controllers).
As a rigid workaround the following could be used:
public interface QueryService {
/**
* Returns all queries.
*
* @return
*/
List<Query> getQueries();
...
}import ru.curs.celesta.SystemCallContext;
...
public class QueryServiceImpl implements QueryService {
...
@Autowired
private QueryServiceImpl self;
...
@Override
public List<Query> getQueries() {
return self.getQueries(new SystemCallContext());
}
@CelestaTransaction
List<Query> getQueries(CallContext cctx) {
try(QueryCursor cursor = new QueryCursor(cctx)) {
...
}
}
...
}what has the disadvantages:
a) Two methods per each service method should are added that again results in a readability digression.
b) No strategy for Celesta’s call context creation can be chosen.
Proposed Changes
It is proposed to introduce the so called CallContextFactory where all needed call contexts would be instantiated for all methods annotated with @CelestaTransaction without CallContext parameter:
public interface CallContextFactory {
CallContext callContext();
}import ru.curs.celesta.CallContext;
import ru.curs.celesta.CallContextFactory;
...
public class QueryServiceImpl implements QueryService {
...
@Autowired
private CallContextFactory cctxf;
...
@Override
@CelestaTransaction
public List<Query> getQueries() {
// Here a default factory provided by Celesta is used whereby
// the strategy of call context instantiation is taken f.g. from
// Celesta properties, or our implementation
// (CallContextFactoryImpl - see below) if provided.
CallContext cctx = cctxf.callContext();
try(QueryCursor cursor = new QueryCursor(cctx)) {
...
}
}
...
}/*
* (optional)
*/
import ru.curs.celesta.CallContext;
import ru.curs.celesta.CallContextFactory;
...
@Primary
@Component
public class CallContextFactoryImpl extends CallContextFactoryBase implements CallContextFactory {
private final String OUR_USER = ...
@Override
protected CallContext createCallContext() {
return new CallContext(OUR_USER);
}
}where
import ru.curs.celesta.CallContext;
import ru.curs.celesta.CallContextFactory;
...
@Component
public abstract class CallContextFactoryBase implements CallContextFactory {
...
public final CallContext callContext() {
// TODO: return activated call context on a per thread basis.
}
...
}Compatibility, Deprecation, and Migration Plan
Current implementation of CelestaTransactionAspect implies that if there is no parameter of CelestaContext type the method is just run without any transaction. In the proposed implementation some transaction would be though opened provided the call context instantiation strategy is indicated or a custom CallContextFactoryImpl is given.
Rejected Alternatives
None.
CIP-7
Metadata
CIP |
7 |
|---|---|
Title |
Explicit numbering of option fields |
Author |
|
Created |
2020-02-14 |
Status |
discussion |
Discussion |
|
JIRA |
N/A |
Motivation
It is pretty convenient to use option fields for automatic generation of enumeratable constants, and later use them in the code which makes it more comprehensive and error resilient. For example grain snippet:
CREATE TABLE Message (
...
/** {option: [DRAFT, SAVED, SENT, QUEUED, RESPONDED, RECEIVED]} */
status INT NOT NULL,
...
}would produce inner static class
public final class MessageCursor extends Cursor implements Iterable<MessageCursor> {
...
public static final class Status {
public static final Integer DRAFT = 0;
public static final Integer SAVED = 1;
public static final Integer SENT = 2;
public static final Integer QUEUED = 3;
public static final Integer RESPONDED = 4;
public static final Integer RECEIVED = 5;
...
}
...
}that looks fine for a freshly written project. Later on however when the project starts to evolve and some new statuses (think option fields) start to appear and old ones disappear and the grain could end up looking like:
CREATE TABLE Message (
...
/** {option: [DRAFT, SAVED, SENT, QUEUED, RESPONDED_DEPRECATED, RECEIVED, NEW]} */
status INT NOT NULL,
...
}which neither reveal the real set of statuses in use nor are the message statuses ordered as they would appear in the message life-cycle.
The second concern is about how to codify statuses starting for example from 100, so that the generation looked like:
public final class MessageCursor extends Cursor implements Iterable<MessageCursor> {
...
public static final class Status {
public static final Integer DRAFT = 100;
public static final Integer SAVED = 101;
public static final Integer SENT = 102;
public static final Integer QUEUED = 103;
public static final Integer RESPONDED = 104;
public static final Integer RECEIVED = 105;
...
}
...
}Proposed Changes
It is proposed to extend the definition syntax of option fields. In two ways:
1) Indicate explicitly codes for option field in round brackets, f.g.:
CREATE TABLE Message (
...
/** {option: [DRAFT(100), SAVED, SENT, QUEUED, RESPONDED(204), RECEIVED]} */
status INT NOT NULL,
...
}would be rendered as:
public final class MessageCursor extends Cursor implements Iterable<MessageCursor> {
...
public static final class Status {
public static final Integer DRAFT = 100;
public static final Integer SAVED = 101;
public static final Integer SENT = 102;
public static final Integer QUEUED = 103;
public static final Integer RESPONDED = 204;
public static final Integer RECEIVED = 205;
...
}
...
}2) Let one or more option fields be simply left out, and thus preserve existing codes like it is done in MS NAV
CREATE TABLE Message (
...
/** {option: [DRAFT, SAVED, SENT, QUEUED, , RECEIVED, NEW]} */
status INT NOT NULL,
...
}would produce inner static class
public final class MessageCursor extends Cursor implements Iterable<MessageCursor> {
...
public static final class Status {
public static final Integer DRAFT = 0;
public static final Integer SAVED = 1;
public static final Integer SENT = 2;
public static final Integer QUEUED = 3;
public static final Integer RESPONDED = 4;
public static final Integer RECEIVED = 5;
public static final Integer NEW = 6;
...
}
...
}Compatibility, Deprecation, and Migration Plan
The proposed changes in the API are backwards compatible with grain syntax of existing solutions.
Rejected Alternatives
None.